Scrapy 爬虫模板--XMLFeedSpider
本文共 1421 字,大约阅读时间需要 4 分钟。
XMLFeedSpider 主要用于 RSS 的爬取。RSS 是基于 XML 的信息局和技术。这篇文章的最后一下小结我会利用爬取经济观察网 RSS 的例子来讲解它的具体用法。现在我们先看一下 XMLFeedSpider 的常用属性。
零、常用属性
- iterator:迭代器,主要用来分析 RSS 源,可用的迭代器有三种:
- iternode:高性能的正则表达式迭代器,是默认迭代器
- html:加载所有的 DOM 结构进行分析,但是如果数据量巨大会产生性能问题。唯一的优点是处理不合理的标签会很有用
- xml:和 html 迭代器类似。
- itertag:指定需要迭代的节点
- namespaces:定义处理文档时所需要使用的命名空间。
一、常用方法
- adapt_response(response):在处理分析 Response 前触发,主要用于修改 Response 的内容,返回类型为 Response 。
- parse_node(response,selectot):怕渠道匹配的节点时触发这个方法处理数据。这个方法必须在项目代码中实现,否则爬虫不工作,并且必须返回 Item、Request 或者包含二者的迭代器。
- process_result(response,result):返回爬取结果时触发,用于将爬取结果传递给框架核心处理前来做最后的修改。
案例
下面我们通过爬取经济观察网的 RSS 来看看 XMLFeedSpider 在实战中怎么用。首先我们来看一下经济观察网的 RSS 结构:
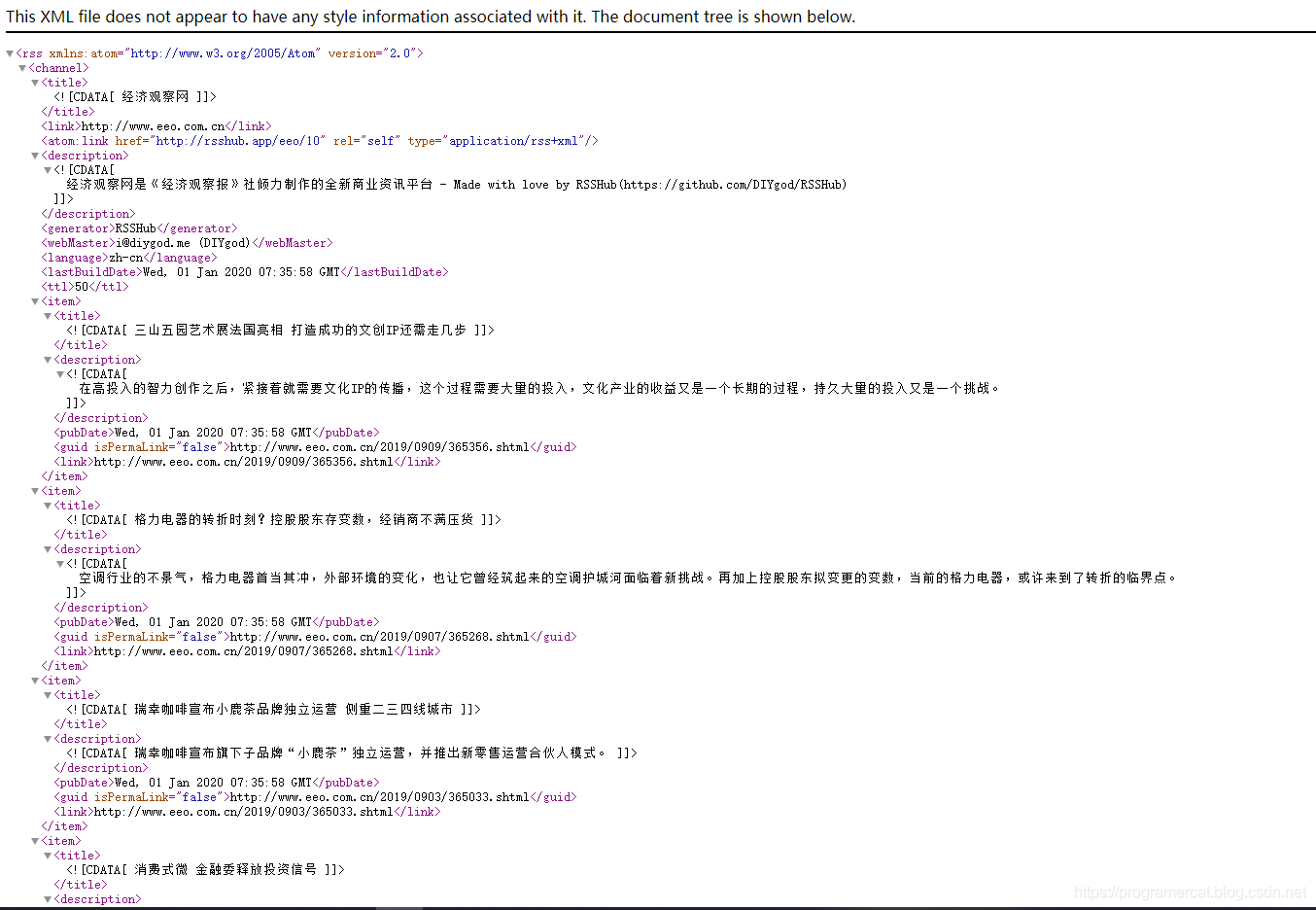
从图中可以看出对我们有用的信息都位于 item 标签之间,那么这个标签之间的内容就是我们需要抓取的东西,这个标签被称为节点。
# -*- coding: utf-8 -*-from scrapy.spiders import XMLFeedSpiderfrom ..items import RsshubItremclass RsshubSpider(XMLFeedSpider): name = 'rsshub' allowed_domains = ['rsshub.app'] start_urls = ['https://rsshub.app/eeo/01'] iterator = 'iternodes' itertag = 'item' def parse_node(self, response, selector): item = RsshubItrem() item['title'] = selector.css("title::text").extract_first() item['public_date'] = selector.css("publicDate::text").extract_first() item['link'] = selector.css("link::text").extract_first() return item import scrapyclass RsshubItrem(scrapy.Item): title = scrapy.Field() public_date = scrapy.Field() link = scrapy.Field() 转载地址:http://swqxf.baihongyu.com/
你可能感兴趣的文章
oracle保存小数点前为"0"的问题
查看>>
ipvsadm 安装配置
查看>>
Linux shell脚本的字符串截取
查看>>
1小时点击量破千万!阿里巴巴首发:MySQL高级调优笔记!全是技术重点
查看>>
这个GItHub上的Java项目开源了 2021最全的Java架构面试复习指南
查看>>
Git神作!2021最新发布Spring Boot高级源码手册(4大主题)看完大厂面试再也不愁了
查看>>
HP-UX oracle RAC 双机实践
查看>>
解决SHELL脚本中的export无法生效的问题【转】
查看>>
区别数据结构中的堆栈与内存中的堆栈的个人总结【转】
查看>>
Android深入浅出之Binder机制
查看>>
linux查看硬件信息
查看>>
linux支持大于4G内存
查看>>
WM_GETINFO相关
查看>>
[收藏] FC交换机基础知识详解
查看>>
Linux调试工具
查看>>
GDB命令大全
查看>>
IT行业培训必读:优秀程序员的十个习惯
查看>>
财务分析与决策:同型分析
查看>>
Android studio出现:Your project path contains non-ASCII characters.
查看>>
Android--Error:Library projects cannot enable Jack. Jack is enabled in default config
查看>>